12.2. Eşzamansız Hesaplama¶ Open the notebook in SageMaker Studio Lab
Günümüzün bilgisayarları, birden fazla CPU çekirdeği (genellikle çekirdek başına birden fazla iş parçacığı), GPU başına birden çok işlem öğesi ve genellikle cihaz başına birden çok GPU’dan oluşan son derece paralel sistemlerdir. Kısacası, birçok farklı şeyi aynı anda, genellikle farklı cihazlarda işleyebiliriz. Ne yazık ki Python, en azından ekstra yardım almadan paralel ve eşzamansız kod yazmanın harika bir yolu değildir. Sonuçta, Python tek iş parçacıklıdır ve bunun gelecekte değişmesi pek olası değil. MXNet ve TensorFlow gibi derin öğrenme çerçeveleri, performansı artırmak için eşzamansız programlama modeli benimser, PyTorch ise Python’un kendi zamanlayıcısını kullanarak farklı bir performans değişimine yol açar. PyTorch için varsayılan olarak GPU işlemleri eşzamansızdır. GPU kullanan bir işlev çağırdığınızda, işlemler belirli bir aygıta sıralanır, ancak daha sonrasına kadar zorunlu olarak yürütülmez. Bu, CPU veya diğer GPU’lardaki işlemler de dahil olmak üzere paralel olarak daha fazla hesaplama yürütmemize olanak tanır.
Bu nedenle, eşzamansız programlamanın nasıl çalıştığını anlamak, hesaplama gereksinimlerini ve karşılıklı bağımlılıkları proaktif azaltarak daha verimli programlar geliştirmemize yardımcı olur. Bu, bellek yükünü azaltmamıza ve işlemci kullanımını artırmamıza olanak tanır.
import os
import subprocess
import numpy
from d2l import mxnet as d2l
from mxnet import autograd, gluon, np, npx
from mxnet.gluon import nn
npx.set_np()
import os
import subprocess
import numpy
import torch
from torch import nn
from d2l import torch as d2l
12.2.1. Arka İşlemci Üzerinden Eşzamanlama¶
Isınmak için aşağıdaki basit örnek problemi göz önünde bulundurun:
Rastgele bir matris oluşturmak ve çarpmak istiyoruz. Farkı görmek için
NumPy ve mxnet.np’te bunu yapalım.
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('mxnet.np'):
for _ in range(10):
a = np.random.normal(size=(1000, 1000))
b = np.dot(a, a)
numpy: 1.4168 sec
mxnet.np: 0.0154 sec
MXNet üzerinden yapılan kıyaslama çıktısı büyüklüğün kuvvetleri mertebesinde daha hızlıdır. Her ikisi de aynı işlemcide çalıştırıldığı için başka bir şey oluyor olmalı. MXNet’i geri dönmeden önce tüm arka işlemciyi hesaplamasını bitirmeye zorlamak, daha önce ne olduğunu gösterir: Ön işlemci, kontrolü Python’a geri verirken hesaplama arka işlemci tarafından yürütülür.
with d2l.Benchmark():
for _ in range(10):
a = np.random.normal(size=(1000, 1000))
b = np.dot(a, a)
npx.waitall()
Done: 1.2114 sec
Genel olarak, MXNet, örneğin Python aracılığıyla kullanıcılarla doğrudan etkileşimler için bir ön işlemciye ve sistem tarafından hesaplamayı gerçekleştirmek için kullanılan bir arka işlemciye sahiptir. Fig. 12.2.1 içinde gösterildiği gibi, kullanıcılar Python, R, Scala ve C++ gibi çeşitli ön işlemci dillerinde MXNet programları yazabilir. Kullanılan ön işlemci programlama dili ne olursa olsun, MXNet programlarının yürütülmesi öncelikle C++ uygulamalarının arka işlemcisinde gerçekleşir. Ön işlemci dili tarafından verilen işlemler yürütme için arka işlemciye iletilir. Arka işlemci, sıraya alınmış görevleri sürekli olarak toplayan ve yürüten kendi iş parçacıklarını yönetir. Bunun çalışması için arka işlemcinin hesaplama çizgesindeki çeşitli adımlar arasındaki bağımlılıkları takip edebilmesi gerektiğini unutmayın. Bu nedenle, birbirine bağlı işlemleri paralel hale getirmek mümkün değildir.
Isınmak için aşağıdaki basit örnek problemi göz önünde bulundurun:
Rastgele bir matris oluşturmak ve çarpmak istiyoruz. Farkı görmek için
bunu hem NumPy hem de PyTorch tensorunda yapalım. PyTorch tensor’ün
bir GPU’da tanımlandığını unutmayın.
# GPU hesaplaması icin isinma
device = d2l.try_gpu()
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('torch'):
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
numpy: 1.4291 sec
torch: 0.0011 sec
PyTorch üzerinden yapılan kıyaslama çıktısı büyüklüğün kuvvetleri mertebesinde daha hızlıdır. NumPy nokta çarpımını CPU işlemcisinde yürütülür ve PyTorch matris çarpımını GPU’da yürütülür ve bu nedenle ikincisinin çok daha hızlı olması beklenir. Ama büyük zaman farkı, başka bir şeyin döndüğünü gösteriyor. Varsayılan olarak, PyTorch’ta GPU işlemleri eşzamansızdır. PyTorch’u geri dönmeden önce tüm hesaplamayı bitirmeye zorlamak daha önce neler olduğunu gösterir: Hesaplama arka işlemci tarafından yürütülür ve ön işlemci denetimi Python’a döndürür.
with d2l.Benchmark():
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
torch.cuda.synchronize(device)
Done: 0.0032 sec
Genel olarak, PyTorch, örneğin Python aracılığıyla kullanıcılarla doğrudan etkileşimler için bir ön işlemciye ve sistem tarafından hesaplamayı gerçekleştirmek için kullanılan bir arka işlemciye sahiptir. Fig. 12.2.1 içinde gösterildiği gibi, kullanıcılar Python, R, Scala ve C++ gibi çeşitli ön işlemci dillerinde PyTorch programları yazabilir. Kullanılan ön işlemci programlama dili ne olursa olsun, PyTorch programlarının yürütülmesi öncelikle C++ uygulamalarının arka işlemcisinde gerçekleşir. Ön yüz dili tarafından verilen işlemler yürütme için arka işlemciye iletilir. Arka işlemci, sıraya alınmış görevleri sürekli olarak toplayan ve yürüten kendi iş parçacıklarını yönetir. Bunun çalışması için arka işlemcinin hesaplama çizgesindeki çeşitli adımlar arasındaki bağımlılıkları takip edebilmesi gerektiğini unutmayın. Bu nedenle, birbirine bağlı işlemleri paralel hale getirmek mümkün değildir.
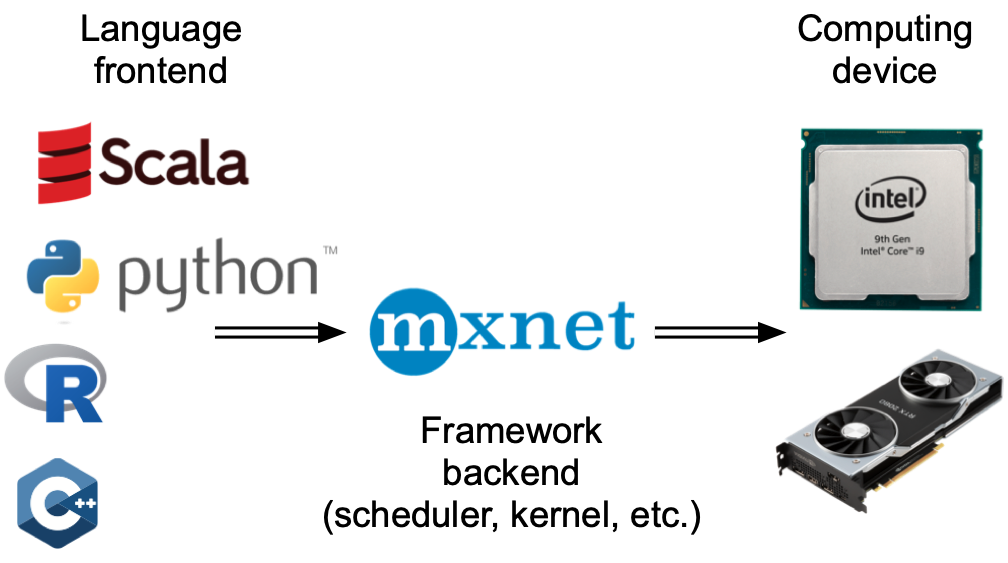
Fig. 12.2.1 Programlama dili ön işlemcileri ve derin öğrenme çerçevesi arka işlemcileri.¶
Bağımlılık çizgesini biraz daha iyi anlamak için başka bir basit örnek probleme bakalım.
x = np.ones((1, 2))
y = np.ones((1, 2))
z = x * y + 2
z
array([[3., 3.]])
x = torch.ones((1, 2), device=device)
y = torch.ones((1, 2), device=device)
z = x * y + 2
z
tensor([[3., 3.]], device='cuda:0')

Fig. 12.2.2 Arka işlemci, hesaplama çizgesindeki çeşitli adımlar arasındaki bağımlılıkları izler.¶
Yukarıdaki kod parçacığı da Fig. 12.2.2 içinde
gösterilmiştir. Python ön işlemci iş parçacığı ilk üç ifadeden birini
çalıştırdığında, görevi arka işlemci kuyruğuna döndürür. Son ifadenin
sonuçları yazdırılmış olması gerektiğinde, Python ön işlemci iş
parçacığı C++ arka işlemci iş parçacığının z değişkenin sonucunu
hesaplamayı tamamlamasını bekler. Bu tasarımın bir avantajı, Python ön
işlemci iş parçacığının gerçek hesaplamaları gerçekleştirmesine gerek
olmadığıdır. Böylece, Python’un performansından bağımsız olarak
programın genel performansı üzerinde çok etkisi yoktur.
Fig. 12.2.3, ön işlemci ve arka işlemcinin nasıl
etkileşime girdiğini gösterir.

Fig. 12.2.3 Ön ve arka işlemci etkileşimleri.¶
12.2.2. Engeller ve Engelleyiciler¶
Python’u tamamlanmasını beklemeye zorlayacak bir dizi işlem vardır:
Açıkçası
npx.waitall(), hesaplama talimatlarının ne zaman verildiğine bakılmaksızın tüm hesaplama tamamlanana kadar bekler. Pratikte, kötü performansa yol açabileceğinden kesinlikle gerekli olmadıkça bu operatörü kullanmak kötü bir fikirdir.Belirli bir değişken kullanılabilir olana kadar beklemek istiyorsak
z.wait_to_read()’i arayabiliriz. Bu durumda MXNet blokları,zdeğişkeni hesaplanıncaya kadar Python’a döner. Diğer hesaplamalar daha sonra devam edebilir.
Bunun pratikte nasıl çalıştığını görelim.
with d2l.Benchmark('waitall'):
b = np.dot(a, a)
npx.waitall()
with d2l.Benchmark('wait_to_read'):
b = np.dot(a, a)
b.wait_to_read()
waitall: 0.0203 sec
wait_to_read: 0.0191 sec
Her iki işlemin de tamamlanması yaklaşık aynı zaman alır. Bariz
engelleme işlemlerinin yanı sıra, örtülü engelleyicilerin farkında
olmanızı öneririz. Bir değişkenin yazdırılması, değişkenin
kullanılabilir olmasını gerektirir ve bu nedenle bir engelleyicidir. Son
olarak, z.asnumpy() aracılığıyla NumPy’ye dönüştürmeler ve
z.item() aracılığıyla skalerlere dönüştürmeler, NumPy’nin
eşzamansızlık kavramı olmadığı için engelleniyor. print işlevi gibi
değerlere erişmesi gerekir.
MXNet’in kapsamından NumPy ve geri sık küçük miktarlarda verilerin kopyalanması, aksi takdirde verimli bir kodun performansını yok edebilir, çünkü bu tür her bir işlem, başka bir şey yapılabilmeden önce ilgili terimi elde ederken gerekli tüm ara sonuçları değerlendirmek için hesaplama çizgesi gerektirir.
with d2l.Benchmark('numpy conversion'):
b = np.dot(a, a)
b.asnumpy()
with d2l.Benchmark('scalar conversion'):
b = np.dot(a, a)
b.sum().item()
numpy conversion: 0.0189 sec
scalar conversion: 0.0489 sec
12.2.3. Hesaplamayı İyileştirme¶
Çok iş parçacıklı bir sistemde (normal dizüstü bilgisayarlarda bile 4
veya daha fazla iş parçacığı vardır ve çok yuvalı sunucularda bu sayı
256’yı geçebilir) zamanlayıcı işlemlerinin ek yükü önemli hale
gelebilir. Bu nedenle hesaplamanın ve zamanlamanın eşzamansız ve paralel
olarak gerçekleşmesi son derece arzu edilir. Bunu yapmanın faydasını
göstermek için, bir değişkeni hem sırayla hem de eşzamansız olarak
birden çok kez 1 artırırsak ne olacağını görelim. Her toplama arasına
bir wait_to_read engelleyicisi ekleyerek eşzamanlı yürütme benzetimi
yapıyoruz.
with d2l.Benchmark('synchronous'):
for _ in range(10000):
y = x + 1
y.wait_to_read()
with d2l.Benchmark('asynchronous'):
for _ in range(10000):
y = x + 1
npx.waitall()
synchronous: 1.6157 sec
asynchronous: 1.0861 sec
Python ön işlemci iş parçacığı ve C++ arka işlemci iş parçacığı
arasındaki biraz basitleştirilmiş bir etkileşim aşağıdaki gibi
özetlenebilir: 1. Ön işlemci, arka işlemcinin y = x + 1’i hesaplama
görevini kuyruğa eklemesini emrediyor. 1. Arka işlemci daha sonra
hesaplama görevlerini kuyruktan alır ve gerçek hesaplamaları
gerçekleştirir. 1. Arka işlemci daha sonra hesaplama sonuçlarını ön
işlemciye döndürür. Bu üç aşamanın sürelerinin sırasıyla
\(t_1, t_2\) ve \(t_3\) olduğunu varsayalım. Eşzamansız
programlama kullanmazsak, 10000 hesaplamaları gerçekleştirmek için
alınan toplam süre yaklaşık \(10000 (t_1+ t_2 + t_3)\)’dir.
Eşzamanlı programlama kullanılıyorsa, 10000 hesaplamayı gerçekleştirmek
için kullanılan toplam süre \(t_1 + 10000 t_2 + t_3\)
(\(10000 t_2 > 9999t_1\) varsayarak) azaltılabilir, çünkü ön işlemci
her döngü için hesaplama sonuçlarını döndürmede beklemek zorunda
değildir.
12.2.4. Özet¶
Derin öğrenme çerçeveleri, Python ön işlemcisini yürütme arka işlemcisinden ayırabilir. Bu, komutların arka işlemciye ve ilişkili paralellik içine hızlı eşzamansız olarak eklenmesine olanak tanır.
Eşzamansızlık oldukça duyarlı bir ön işlemciye yol açar. Ancak, aşırı bellek tüketimine neden olabileceğinden görev kuyruğunu aşırı doldurmamak için dikkatli olun. Ön işlemciyi ve arka işlemciyi yaklaşık olarak senkronize ederken her minigrup için senkronize edilmesi önerilir.
Çip satıcıları, derin öğrenmenin verimliliği hakkında çok daha ince tanımlanmış bir içgörü elde etmek için gelişmiş başarım çözümleme araçları sunar.
MXNet’in bellek yönetiminden Python’a dönüşümlerin arka işlemciyi belirli değişken hazır olana kadar beklemeye zorlayacağını unutmayın.
print,asnumpyveitemgibi işlevlerin hepsi bu etkiye sahiptir. Bu arzu edilebilir, ancak eşzamanlılığın dikkatsiz kullanımı performansı mahvedebilir.
12.2.5. Alıştırmalar¶
Yukarıda, eşzamansız hesaplama kullanmanın, 10000 hesaplamayı gerçekleştirmek için gereken toplam süreyi \(t_1 + 10000 t_2 + t_3\)’a indirebileceğini belirtmiştik. Neden burada \(10000 t_2 > 9999 t_1\)’yi varsaymak zorundayız?
waitallvewait_to_readarasındaki farkı ölçün. İpucu: Bir dizi talimat uygulayın ve bir ara sonuç için senkronize edin.
CPU’da, bu bölümdeki aynı matris çarpma işlemlerini karşılaştırın. Arka işlemci üzerinden hala eşzamansızlık gözlemleyebilir misiniz?