16.2. MovieLens Veri Kümesi¶ Open the notebook in SageMaker Studio Lab
Tavsiye araştırmaları için kullanılabilen bir dizi veri kümesi vardır. Bunların arasında, MovieLens veri kümesi muhtemelen en popüler olanlardan biridir. MovieLens ticari olmayan web tabanlı bir film tavsiye sistemidir. 1997 yılında, Minnesota Üniversitesi’nde bir araştırma laboratuvarı olan GroupLens tarafından araştırma amacıyla film derecelendirme verilerini toplamak için oluşturulmuştur ve işletilmektedir. MovieLens verileri, kişiselleştirilmiş tavsiye ve sosyal psikoloji de dahil olmak üzere çeşitli araştırma çalışmaları için kritik öneme sahiptir.
16.2.1. Verileri Alma¶
MovieLens veri kümesi,
GroupLens web sitesinde
konuşlandırılmaktadır. Birçok sürümü mevcuttur. MovieLens 100K veri
kümesini kullanacağız (Herlocker et al., 1999). Bu
veri kümesi, 1682 filmdeki 943 kullanıcıdan 1 ile 5 yıldız arasında
değişen \(100000\) derecelendirmeden oluşmaktadır. Veri her
kullanıcıdan en az 20 film derecelendirmesi içerecek şekilde temizlendi.
Yaş, cinsiyet, kullanıcılar ve öğeler için türler gibi bazı basit
demografik bilgiler de mevcuttur.
ml-100k.zip’i
indirebilir ve csv formatındaki bütün \(100000\) derecelendirmeyi
içeren u.data dosyasını ayıklayabiliriz. Klasörde başka birçok dosya
bulunur, her dosya için ayrıntılı bir açıklama veri kümesinin
README
dosyasında bulunabilir.
Başlangıç olarak, bu bölümün deneylerini çalıştırmak için gereken paketleri içe aktaralım.
import os
import pandas as pd
from d2l import mxnet as d2l
from mxnet import gluon, np
Ardından, MovieLens 100k veri kümesini indirir ve etkileşimleri
DataFrame olarak yükleriz.
#@save
d2l.DATA_HUB['ml-100k'] = (
'https://files.grouplens.org/datasets/movielens/ml-100k.zip',
'cd4dcac4241c8a4ad7badc7ca635da8a69dddb83')
#@save
def read_data_ml100k():
data_dir = d2l.download_extract('ml-100k')
names = ['user_id', 'item_id', 'rating', 'timestamp']
data = pd.read_csv(os.path.join(data_dir, 'u.data'), '\t', names=names,
engine='python')
num_users = data.user_id.unique().shape[0]
num_items = data.item_id.unique().shape[0]
return data, num_users, num_items
16.2.2. Veri Kümesinin İstatistikleri¶
Verileri yükleyelim ve ilk beş kaydı elden inceleyelim. Bu, veri yapısını öğrenmek ve düzgün yüklendiklerini doğrulamak için etkili bir yoldur.
data, num_users, num_items = read_data_ml100k()
sparsity = 1 - len(data) / (num_users * num_items)
print(f'number of users: {num_users}, number of items: {num_items}')
print(f'matrix sparsity: {sparsity:f}')
print(data.head(5))
number of users: 943, number of items: 1682
matrix sparsity: 0.936953
user_id item_id rating timestamp
0 196 242 3 881250949
1 186 302 3 891717742
2 22 377 1 878887116
3 244 51 2 880606923
4 166 346 1 886397596
Her satırın “user id” (kullanıcı kimliği) 1-943, “item id” (öğe kimliği)
1-1682, “rating” (derecelendirme) 1-5 ve “timestamp” (zaman damgası)
dahil olmak üzere dört sütundan oluştuğunu görebiliriz.
\(n \times m\) boyutlarında bir etkileşim matrisi oluşturabiliriz,
burada \(n\) ve \(m\) sırasıyla kullanıcı sayısı ve öğe
sayısıdır. Bu veri kümesi yalnızca mevcut derecelendirmeleri kaydeder,
bu nedenle buna derecelendirme matrisi diyebiliriz ve bu matrisin
değerlerinin tam derecelendirmeleri temsil etmesi durumunda etkileşim
matrisi ve derecelendirme matrisini birbirinin yerine kullanacağız.
Kullanıcılar filmlerin çoğunu derecelendirmediğinden derecelendirme
matrisindeki değerlerin çoğu bilinmemektedir. Ayrıca bu veri kümesinin
seyrek olduğunu da gösteriyoruz. Seyreklik
1 - number of nonzero entries / ( number of users * number of items)
( 1 - sıfır olmayan girdiler / (kullanıcı sayısı * öğe sayısı)) olarak
tanımlanır. Açıkçası, etkileşim matrisi son derece seyrektir (yani,
seyreklik = 93.695%). Gerçek dünya veri kümeleri, daha büyük ölçüde
seyreklik yaşayabilir ve tavsiye sistemlerinin oluşturulmasında uzun
süredir devam eden bir zorluk olmuştur. Kullanıcı/öğe öznitelikleri gibi
ek yan bilgileri kullanmak için uygulanabilir bir çözüm, seyrekliği
hafifletmektir.
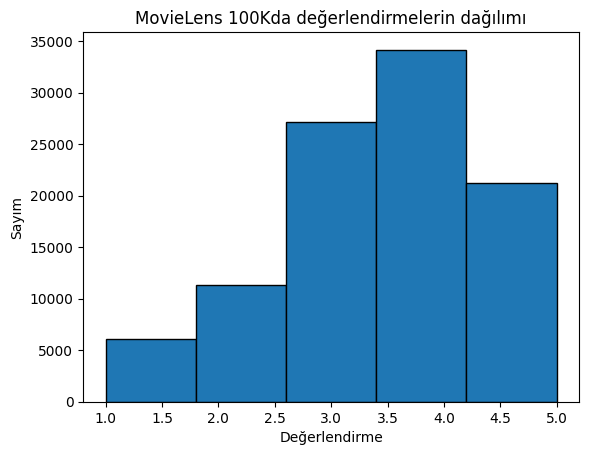
Daha sonra farklı derecelendirme sayımlarının dağılımını çizdiriyoruz. Beklendiği gibi, normal bir dağılım gibi görünüyor ve çoğu derecelendirme 3-4 olarak ortalanmıştır.
d2l.plt.hist(data['rating'], bins=5, ec='black')
d2l.plt.xlabel('Değerlendirme')
d2l.plt.ylabel('Sayım')
d2l.plt.title('MovieLens 100Kda değerlendirmelerin dağılımı')
d2l.plt.show()
16.2.3. Veri Kümesini Bölme¶
Veri kümesini eğitim ve test kümelerine ayırdık. Aşağıdaki işlev
random ve seq-aware dahil olmak üzere iki bölünmüş mod sağlar.
random modunda, fonksiyon 100 bin etkileşimi zaman damgası dikkate
almadan rastgele böler ve varsayılan olarak verilerin %90’ını eğitim
örnekleri, geri kalanın %10’unu test örnekleri olarak kullanır.
seq-aware modunda, bir kullanıcının test için en son puan aldığı
öğeyi ve kullanıcıların eğitim kümesi olarak tarihsel etkileşimlerini
bırakıyoruz. Kullanıcı geçmişi etkileşimleri, zaman damgasına göre en
eskisinden en yeniye sıralanır. Bu mod, sıraya duyarlı tavsiye bölümünde
kullanılır.
#@save
def split_data_ml100k(data, num_users, num_items,
split_mode='random', test_ratio=0.1):
"""Veri kümesini rastgele modda veya sıraya duyarlı modda böl."""
if split_mode == 'seq-aware':
train_items, test_items, train_list = {}, {}, []
for line in data.itertuples():
u, i, rating, time = line[1], line[2], line[3], line[4]
train_items.setdefault(u, []).append((u, i, rating, time))
if u not in test_items or test_items[u][-1] < time:
test_items[u] = (i, rating, time)
for u in range(1, num_users + 1):
train_list.extend(sorted(train_items[u], key=lambda k: k[3]))
test_data = [(key, *value) for key, value in test_items.items()]
train_data = [item for item in train_list if item not in test_data]
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
else:
mask = [True if x == 1 else False for x in np.random.uniform(
0, 1, (len(data))) < 1 - test_ratio]
neg_mask = [not x for x in mask]
train_data, test_data = data[mask], data[neg_mask]
return train_data, test_data
Yalnızca bir test kümesi dışında, pratikte bir geçerleme kümesi kullanmanın iyi bir uygulama olduğunu unutmayın. Ancak, kısalık uğruna bunu burada atlıyoruz. Bu durumda, test kümemiz dışarıda tutulan geçerleme kümemiz olarak kabul edilebilir.
16.2.4. Veriyi Yükleme¶
Veri kümesinin bölünmesinden sonra, eğitim kümesini ve test kümesini
kolaylık sağlamak için listelere ve sözlüklere/matrise dönüştüreceğiz.
Aşağıdaki işlev, veri çerçevesini satır satır okur ve
kullanıcıların/öğelerin dizinini sıfırdan başlatır. İşlev daha sonra
kullanıcılar, öğeler, derecelendirmeler listelerini ve etkileşimleri
kaydeden bir sözlük/matris döndürür. Geri bildirim türünü explicit
(açık) veya implicit (örtük) diye belirtebiliriz.
#@save
def load_data_ml100k(data, num_users, num_items, feedback='explicit'):
users, items, scores = [], [], []
inter = np.zeros((num_items, num_users)) if feedback == 'explicit' else {}
for line in data.itertuples():
user_index, item_index = int(line[1] - 1), int(line[2] - 1)
score = int(line[3]) if feedback == 'explicit' else 1
users.append(user_index)
items.append(item_index)
scores.append(score)
if feedback == 'implicit':
inter.setdefault(user_index, []).append(item_index)
else:
inter[item_index, user_index] = score
return users, items, scores, inter
Daha sonra yukarıdaki adımları bir araya getiriyoruz ve bir sonraki
bölümde kullanacağız. Sonuçlar Dataset ve DataLoader ile
sarmalanır. Eğitim verileri için DataLoader’ın (VeriYineleyici)
last_batch’inin (son toplu iş) rollover (çevirme) moduna
ayarlandığını (kalan örnekler bir sonraki döneme aktarılır) ve sıraların
karıştırıldığını unutmayın.
#@save
def split_and_load_ml100k(split_mode='seq-aware', feedback='explicit',
test_ratio=0.1, batch_size=256):
data, num_users, num_items = read_data_ml100k()
train_data, test_data = split_data_ml100k(
data, num_users, num_items, split_mode, test_ratio)
train_u, train_i, train_r, _ = load_data_ml100k(
train_data, num_users, num_items, feedback)
test_u, test_i, test_r, _ = load_data_ml100k(
test_data, num_users, num_items, feedback)
train_set = gluon.data.ArrayDataset(
np.array(train_u), np.array(train_i), np.array(train_r))
test_set = gluon.data.ArrayDataset(
np.array(test_u), np.array(test_i), np.array(test_r))
train_iter = gluon.data.DataLoader(
train_set, shuffle=True, last_batch='rollover',
batch_size=batch_size)
test_iter = gluon.data.DataLoader(
test_set, batch_size=batch_size)
return num_users, num_items, train_iter, test_iter
16.2.5. Özet¶
MovieLens veri kümeleri, tavsiye araştırmaları için yaygın olarak kullanılmaktadır. Kamuya açıktır ve kullanımı ücretsizdir.
MovieLens 100k veri kümesini daha sonraki bölümlerde kullanmak üzere indirmek ve ön işlemek için işlevler tanımlıyoruz.
16.2.6. Alıştırmalar¶
Başka hangi benzer tavsiye veri kümelerini bulabilirsiniz?
MovieLens hakkında daha fazla bilgi için https://movielens.org/ sitesini ziyaret edin.