4.10. Kaggle’da Ev Fiyatlarını Tahmin Etme¶ Open the notebook in SageMaker Studio Lab
Artık derin ağlar oluşturmak ve eğitmek için bazı temel araçları sunduğumuza ve bunları ağırlık sönümü ve hattan düşürme gibi tekniklerle düzenlileştirdiğimize göre, tüm bu bilgileri bir Kaggle yarışmasına katılarak uygulamaya koymaya hazırız. Ev fiyat tahmini yarışması başlangıç için harika bir yerdir. Veriler oldukça geneldir ve özel modeller gerektirebilecek (ses veya video gibi) acayip yapılar sergilememektedir. Bart de Cock tarafından 2011 yılında toplanan bu veri kümesi, (De Cock, 2011), 2006–2010 döneminden itibaren Ames, IA’daki ev fiyatlarını kapsamaktadır. Harrison ve Rubinfeld’in (1978) ünlü Boston konut veri kümesi’nden önemli ölçüde daha büyüktür ve hem fazla örneğe, hem de daha fazla özniteliğe sahiptir.
Bu bölümde, veri ön işleme, model tasarımı ve hiper parametre seçimi ayrıntılarında size yol göstereceğiz. Uygulamalı bir yaklaşımla, bir veri bilimcisi olarak kariyerinizde size rehberlik edecek bazı sezgiler kazanacağınızı umuyoruz.
4.10.1. Veri Kümelerini İndirme ve Önbelleğe Alma¶
Kitap boyunca, indirilen çeşitli veri kümeleri üzerinde modelleri
eğitecek ve test edeceğiz. Burada, veri indirmeyi kolaylaştırmak için
çeşitli yardımcı fonksiyonlar gerçekleştiriyoruz. İlk olarak, bir dizeyi
(veri kümesinin adını) hem veri kümesini bulmak için URL’yi hem de
dosyanın bütünlüğünü doğrulamak için kullanacağımız SHA-1’i anahtarı
içeren bir çokuzluya eşleyen bir DATA_HUB sözlüğü tutuyoruz. Tüm bu
tür veri kümeleri, adresi DATA_URL’ye atanan sitede
barındırılmaktadır.
import hashlib
import os
import tarfile
import zipfile
import requests
#@save
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
Aşağıdaki download işlevi, bir veri kümesini indirir, yerel bir
dizinde (varsayılan olarak ../data) önbelleğe alır ve indirilen
dosyanın adını döndürür. Bu veri kümesine karşılık gelen bir dosya
önbellek dizininde zaten mevcutsa ve SHA-1’i DATA_HUB’da depolananla
eşleşiyorsa, kodumuz internetinizi gereksiz indirmelerle tıkamamak için
önbelleğe alınmış dosyayı kullanacaktır.
def download(name, cache_dir=os.path.join('..', 'data')): #@save
"""DATA_HUB'a eklenen bir dosyayı indir, yerel dosya adını döndür."""
assert name in DATA_HUB, f"{name} does not exist in {DATA_HUB}."
url, sha1_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True)
fname = os.path.join(cache_dir, url.split('/')[-1])
if os.path.exists(fname):
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
if sha1.hexdigest() == sha1_hash:
return fname # Hit cache
print(f'Downloading {fname} from {url}...')
r = requests.get(url, stream=True, verify=True)
with open(fname, 'wb') as f:
f.write(r.content)
return fname
Ayrıca iki ek fayda işlevini de gerçekleştiriyoruz: Biri bir zip veya
tar dosyasını indirip çıkarmak, diğeri ise bu kitapta kullanılan veri
kümelerinin tümünü DATA_HUB’dan önbellek dizinine indirmek.
def download_extract(name, folder=None): #@save
"""Bir zip/tar dosyası indir ve aç."""
fname = download(name)
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, 'Only zip/tar files can be extracted.'
fp.extractall(base_dir)
return os.path.join(base_dir, folder) if folder else data_dir
def download_all(): #@save
"""DATA_HUB içindeki tüm dosyaları indir."""
for name in DATA_HUB:
download(name)
4.10.2. Kaggle¶
Kaggle, makine öğrenmesi yarışmalarına ev sahipliği yapan popüler bir platformdur. Her yarışma bir veri kümesine odaklanır ve çoğu, kazanan çözümlere ödüller sunan paydaşlar tarafından desteklenir. Platform, kullanıcıların forumlar ve paylaşılan kodlar aracılığıyla etkileşime girmesine yardımcı olarak hem işbirliğini hem de rekabeti teşvik eder. Liderlik tahtası takibi çoğu zaman kontrolden çıkarken, araştırmacılar temel sorular sormaktan ziyade ön işleme adımlarına yakın olarak odaklanırken, bir platformun nesnelliğinde rakip yaklaşımlar arasında doğrudan nicel karşılaştırmaları ve böylece neyin işe yarayıp yaramadığını herkes öğrenebileceği kod paylaşımını kolaylaştıran muazzam bir değer vardır. Bir Kaggle yarışmasına katılmak istiyorsanız, önce bir hesap açmanız gerekir (bakınız Fig. 4.10.1).
Fig. 4.10.1 Kaggle web sitesi¶
Ev fiyatları tahminleme yarışması sayfasında, Fig. 4.10.2 içinde gösterildiği gibi, veri kümesini bulabilir (“Data” sekmesinin altında), tahminleri gönderebilir ve sıralamanıza bakabilirsiniz. URL tam buradadır:
Fig. 4.10.2 Ev fiyatları tahminleme yarışması sayfası¶
4.10.3. Veri Kümesine Erişim ve Okuma¶
Yarışma verilerinin eğitim ve test kümelerine ayrıldığını unutmayın. Her kayıt, evin mülk değerini ve sokak tipi, yapım yılı, çatı tipi, bodrum durumu vb. öznitelikleri içerir. Öznitelikler çeşitli veri türlerinden oluşur. Örneğin, yapım yılı bir tamsayı ile, çatı tipi ayrı kategorik atamalarla ve diğer öznitelikler kayan virgüllü sayılarla temsil edilir. Böylece burada gerçeklik işleri zorlaştırmaya başlar: Bazı örnekler için, bazı veriler tamamen eksiktir ve eksik değer sadece “na” olarak işaretlenmiştir. Her evin fiyatı sadece eğitim kümesi için dahildir (sonuçta bu bir yarışmadır). Bir geçerleme kümesi oluşturmak için eğitim kümesini bölümlere ayırmak isteyeceğiz, ancak modellerimizi yalnızca tahminleri Kaggle’a yükledikten sonra resmi test kümesinde değerlendirebiliriz. Fig. 4.10.2 içindeki yarışma sekmesindeki “Data” sekmesi, verileri indirmek için bağlantılar içerir.
Başlamak için, verileri Section 2.2 içinde tanıttığımız
pandas’ı kullanarak okuyup işleyeceğiz. Bu nedenle devam etmeden
önce pandas’ı kurduğunuza emin olmak isteyeceksiniz. Neyse ki,
Jupyter’de okuyorsanız, pandas’ı not defterinden bile çıkmadan
kurabiliriz.
# Pandas kurulu değilse, lütfen aşağıdaki satırın yorumunu kaldırın:
# !pip install pandas
%matplotlib inline
import pandas as pd
from d2l import mxnet as d2l
from mxnet import autograd, gluon, init, np, npx
from mxnet.gluon import nn
npx.set_np()
# Pandas kurulu değilse, lütfen aşağıdaki satırın yorumunu kaldırın:
# !pip install pandas
%matplotlib inline
import numpy as np
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
# Pandas kurulu değilse, lütfen aşağıdaki satırın yorumunu kaldırın:
# !pip install pandas
%matplotlib inline
import numpy as np
import pandas as pd
import tensorflow as tf
from d2l import tensorflow as d2l
Kolaylık olması için, yukarıda tanımladığımız komut dosyasını kullanarak Kaggle konut veri kümesini indirebilir ve önbelleğe alabiliriz.
DATA_HUB['kaggle_house_train'] = ( #@save
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce')
DATA_HUB['kaggle_house_test'] = ( #@save
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90')
Sırasıyla eğitim ve test verilerini içeren iki csv dosyasını yüklemek
için pandas’ı kullanıyoruz.
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
Eğitim veri kümesi 1460 tane örnek, 80 tane öznitelik ve 1 tane etiket içerirken, test verileri 1459 tane örnek ve 80 tane öznitelik içerir.
print(train_data.shape)
print(test_data.shape)
(1460, 81)
(1459, 80)
print(train_data.shape)
print(test_data.shape)
(1460, 81)
(1459, 80)
print(train_data.shape)
print(test_data.shape)
(1460, 81)
(1459, 80)
İlk dört örnekten etiketin (SalePrice - SatışFiyatı) yanı sıra ilk dört ve son iki özniteliğe bir göz atalım.
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
print(train_data.iloc[0:4, [0, 1, 2, 3, -3, -2, -1]])
Id MSSubClass MSZoning LotFrontage SaleType SaleCondition SalePrice
0 1 60 RL 65.0 WD Normal 208500
1 2 20 RL 80.0 WD Normal 181500
2 3 60 RL 68.0 WD Normal 223500
3 4 70 RL 60.0 WD Abnorml 140000
Her örnekte ilk özniteliğin kimlik numarası olduğunu görebiliriz. Bu, modelin her eğitim örneğini tanımlamasına yardımcı olur. Bu uygun olsa da, tahmin amaçlı herhangi bir bilgi taşımaz. Bu nedenle, verileri modele beslemeden önce veri kümesinden kaldırıyoruz.
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
4.10.4. Veri Ön İşleme¶
Yukarıda belirtildiği gibi, çok çeşitli veri türlerine sahibiz. Modellemeye başlamadan önce verileri ön işlememiz gerekecek. Sayısal özniteliklerle başlayalım. İlk olarak, tüm eksik değerleri karşılık gelen özniteliğin ortalaması ile değiştiren bir buluşsal yöntem uygularız. Ardından, tüm öznitelikleri ortak bir ölçeğe koymak için, onları sıfır ortalamaya ve birim varyansa yeniden ölçeklendirerek standardize ederiz:
burada \(\mu\) ve \(\sigma\) sırasıyla ortalamayı ve standard sapmayı ifade eder. Bunun özniteliği (değişkenimizi) sıfır ortalamaya ve birim varyansına sahip olacak şekilde dönüştürdüğünü doğrulamak için, \(E[\frac{x-\mu}{\sigma}] = \frac{\mu - \mu}{\sigma} = 0\) ve \(E[(x-\mu)^2] = (\sigma^2 + \mu^2) - 2\mu^2+\mu^2 = \sigma^2\) olduğuna dikkat edin. Sezgisel olarak, verileri iki nedenden dolayı standartleştiriyoruz. Birincisi, optimizasyon için uygun oluyor. İkinci olarak, hangi özniteliklerin ilgili olacağını önsel bilmediğimiz için, bir özniteliğe atanan katsayıları diğerlerinden daha fazla cezalandırmak istemiyoruz.
# Test verilerine erişilemiyorsa, eğitim verilerinden
# ortalama ve standart sapma hesaplanabilir
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# # Verileri standartlaştırdıktan sonra her şey yok olur,
# dolayısıyla eksik değerleri 0 olarak ayarlayabiliriz.
all_features[numeric_features] = all_features[numeric_features].fillna(0)
Daha sonra ayrık değerlerle ilgileniyoruz. Bu, “MSZoning” gibi
değişkenleri içerir. Onları daha önce çok sınıflı etiketleri vektörlere
dönüştürdüğümüz gibi (bkz. Section 3.4.1)
bire bir kodlama ile değiştiriyoruz. Örneğin, “MSZoning”, “RL” ve “RM”
değerlerini varsayar. “MSZoning” özniteliğini kaldırılarak,
“MSZoning_RL” ve “MSZoning_RM” olmak üzere iki yeni gösterge
özniteliğini 0 veya 1 değerleriyle oluşturulur. Bire bir kodlamaya göre,
“MSZoning“‘in orijinal değeri “RL” ise, “MSZoning_RL” 1’dir ve
“MSZoning_RM” 0’dır. pandas paketi bunu bizim için otomatik olarak
yapar.
# # `Dummy_na=True`, "na"yı (eksik değer) geçerli bir öznitelik değeri olarak
# kabul eder ve bunun için bir gösterge özniteliği oluşturur
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(2919, 331)
# # `Dummy_na=True`, "na"yı (eksik değer) geçerli bir öznitelik değeri olarak
# kabul eder ve bunun için bir gösterge özniteliği oluşturur
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(2919, 331)
# # `Dummy_na=True`, "na"yı (eksik değer) geçerli bir öznitelik değeri olarak
# kabul eder ve bunun için bir gösterge özniteliği oluşturur
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape
(2919, 331)
Bu dönüşümün özelliklerin sayısını 79’dan 331’e çıkardığını
görebilirsiniz. Son olarak, values özelliğiyle, NumPy formatını
pandas veri formatından çıkarabilir ve eğitim için tensör temsiline
dönüştürebiliriz.
n_train = train_data.shape[0]
train_features = np.array(all_features[:n_train].values, dtype=np.float32)
test_features = np.array(all_features[n_train:].values, dtype=np.float32)
train_labels = np.array(
train_data.SalePrice.values.reshape(-1, 1), dtype=np.float32)
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32)
n_train = train_data.shape[0]
train_features = tf.constant(all_features[:n_train].values, dtype=tf.float32)
test_features = tf.constant(all_features[n_train:].values, dtype=tf.float32)
train_labels = tf.constant(
train_data.SalePrice.values.reshape(-1, 1), dtype=tf.float32)
4.10.5. Eğitim¶
Başlarken, hata karesi kullanan doğrusal bir model eğitiyoruz. Şaşırtıcı olmayan bir şekilde, doğrusal modelimiz rekabeti kazanan bir teslime yol açmayacaktır, ancak verilerde anlamlı bilgi olup olmadığını görmek için bir makulluk kontrolü sağlar. Burada rastgele tahmin etmekten daha iyisini yapamazsak, o zaman bir veri işleme hatasına sahip olma ihtimalimiz yüksek olabilir. Eğer işler yolunda giderse, doğrusal model bize basit modelin en iyi rapor edilen modellere ne kadar yaklaştığı konusunda biraz önsezi vererek daha süslü modellerden ne kadar kazanç beklememiz gerektiğine dair bir fikir verir.
loss = gluon.loss.L2Loss()
def get_net():
net = nn.Sequential()
net.add(nn.Dense(1))
net.initialize()
return net
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,1))
return net
loss = tf.keras.losses.MeanSquaredError()
def get_net():
net = tf.keras.models.Sequential()
net.add(tf.keras.layers.Dense(
1, kernel_regularizer=tf.keras.regularizers.l2(weight_decay)))
return net
Konut fiyatlarında, hisse senedi fiyatlarında olduğu gibi, göreceli miktarları mutlak miktarlardan daha fazla önemsiyoruz. Bu nedenle, \(\frac{y - \hat{y}}{y}\) göreceli hatasını \(y - \hat{y}\) mutlak hatasından daha çok önemsiyoruz. Örneğin, tipik bir evin değerinin 125000 Amerikan Doları olduğu Rural Ohio’daki bir evin fiyatını tahmin ederken tahminimiz 100000 USD yanlışsa, muhtemelen korkunç bir iş yapıyoruz demektir. Öte yandan, Los Altos Hills, California’da bu miktarda hata yaparsak, bu şaşırtıcı derecede doğru bir tahmini temsil edebilir (burada, ortalama ev fiyatı 4 milyon Amerikan Dolarını aşar).
Bu sorunu çözmenin bir yolu, fiyat tahminlerinin logaritmasındaki tutarsızlığı ölçmektir. Aslında, bu aynı zamanda yarışma tarafından gönderimlerin kalitesini değerlendirmek için kullanılan resmi hata ölçüsüdür. Sonuçta, küçük bir \(\delta\) için \(|\log y - \log \hat{y}| \leq \delta\) değerini \(e^{-\delta} \leq \frac{\hat{y}}{y} \leq e^\delta\)’e çevirir. Bu da tahmini fiyat logaritması ile etiket fiyat logaritması arasında aşağıdaki ortalama kare hata kare kökü kaybına yol açar:
def log_rmse(net, features, labels):
# Logaritma alındığında değeri daha da sabitlemek için
# 1'den küçük değeri 1 olarak ayarlayın
clipped_preds = np.clip(net(features), 1, float('inf'))
return np.sqrt(2 * loss(np.log(clipped_preds), np.log(labels)).mean())
def log_rmse(net, features, labels):
# Logaritma alındığında değeri daha da sabitlemek için
# 1'den küçük değeri 1 olarak ayarlayın
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
def log_rmse(y_true, y_pred):
# Logaritma alındığında değeri daha da sabitlemek için
# 1'den küçük değeri 1 olarak ayarlayın
clipped_preds = tf.clip_by_value(y_pred, 1, float('inf'))
return tf.sqrt(tf.reduce_mean(loss(
tf.math.log(y_true), tf.math.log(clipped_preds))))
Önceki bölümlerden farklı olarak, eğitim işlevlerimiz Adam optimize edicisine dayanacaktır (daha sonra daha ayrıntılı olarak açıklayacağız). Bu eniyileyicinin ana cazibesi hiper parametre optimizasyonu için sınırsız kaynaklar verildiğinde daha iyisini yapmamasına (ve bazen daha kötüsünü yapmasına) rağmen, insanların başlangıç öğrenme oranına önemli ölçüde daha az duyarlı olduğunu bulma eğiliminde olmasıdır.
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# Burada Adam optimizasyon algoritması kullanılıyor
trainer = gluon.Trainer(net.collect_params(), 'adam', {
'learning_rate': learning_rate, 'wd': weight_decay})
for epoch in range(num_epochs):
for X, y in train_iter:
with autograd.record():
l = loss(net(X), y)
l.backward()
trainer.step(batch_size)
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# Burada Adam optimizasyon algoritması kullanılıyor
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# Burada Adam optimizasyon algoritması kullanılıyor
optimizer = tf.keras.optimizers.Adam(learning_rate)
net.compile(loss=loss, optimizer=optimizer)
for epoch in range(num_epochs):
for X, y in train_iter:
with tf.GradientTape() as tape:
y_hat = net(X)
l = loss(y, y_hat)
params = net.trainable_variables
grads = tape.gradient(l, params)
optimizer.apply_gradients(zip(grads, params))
train_ls.append(log_rmse(train_labels, net(train_features)))
if test_labels is not None:
test_ls.append(log_rmse(test_labels, net(test_features)))
return train_ls, test_ls
4.10.6. \(K\)-Kat Çapraz-Geçerleme¶
Model seçimiyle nasıl başa çıkılacağını tartıştığımız bölümde \(K\)-kat çapraz geçerlemeyi tanıttığımızı hatırlayabilirsiniz (Section 4.4). Bunu, model tasarımını seçmek ve hiper parametreleri ayarlamak için iyi bir şekilde kullanacağız. Öncelikle, \(K\)-kat çapraz geçerleme prosedüründe verilerin \(i.\) katını döndüren bir işleve ihtiyacımız var. \(i.\) parçayı geçerleme verisi olarak dilimleyerek ve geri kalanını eğitim verisi olarak döndürerek ilerler. Bunun veri işlemenin en verimli yolu olmadığını ve veri kümemiz çok daha büyük olsaydı kesinlikle çok daha akıllıca bir şey yapacağımızı unutmayın. Ancak bu ek karmaşıklık, kodumuzu gereksiz yere allak bullak edebilir, bu nedenle sorunumuzun basitliğinden dolayı burada güvenle atlayabiliriz.
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = np.concatenate([X_train, X_part], 0)
y_train = np.concatenate([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = tf.concat([X_train, X_part], 0)
y_train = tf.concat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
Eğitim ve geçerleme hatası ortalamaları, \(K\)-kat çapraz geçerleme ile \(K\) kez eğitimimizde döndürülür.
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'fold {i + 1}, train log rmse {float(train_ls[-1]):f}, '
f'valid log rmse {float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
4.10.7. Model Seçimi¶
Bu örnekte, ayarlanmamış bir hiper parametre kümesi seçiyoruz ve modeli geliştirmek için okuyucuya bırakıyoruz. İyi bir seçim bulmak, kişinin kaç değişkeni optimize ettiğine bağlı olarak zaman alabilir. Yeterince büyük bir veri kümesi ve normal hiper parametreler ile \(K\)-kat çapraz geçerleme, çoklu testlere karşı makul ölçüde dirençli olma eğilimindedir. Bununla birlikte, mantıksız bir şekilde çok sayıda seçeneği denersek, sadece şanslı olabiliriz ve geçerleme performansımızın artık gerçek hatayı temsil etmediğini görebiliriz.
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-fold validation: avg train log rmse: {float(train_l):f}, '
f'avg valid log rmse: {float(valid_l):f}')
[21:55:48] src/base.cc:49: GPU context requested, but no GPUs found.
fold 1, train log rmse 0.169779, valid log rmse 0.157055
fold 2, train log rmse 0.162381, valid log rmse 0.189086
fold 3, train log rmse 0.163611, valid log rmse 0.167944
fold 4, train log rmse 0.167617, valid log rmse 0.154766
fold 5, train log rmse 0.163050, valid log rmse 0.182899
5-fold validation: avg train log rmse: 0.165288, avg valid log rmse: 0.170350

k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-fold validation: avg train log rmse: {float(train_l):f}, '
f'avg valid log rmse: {float(valid_l):f}')
fold 1, train log rmse 0.170226, valid log rmse 0.156672
fold 2, train log rmse 0.162236, valid log rmse 0.190424
fold 3, train log rmse 0.163491, valid log rmse 0.168458
fold 4, train log rmse 0.168297, valid log rmse 0.154856
fold 5, train log rmse 0.163502, valid log rmse 0.182911
5-fold validation: avg train log rmse: 0.165550, avg valid log rmse: 0.170664

k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-fold validation: avg train log rmse: {float(train_l):f}, '
f'avg valid log rmse: {float(valid_l):f}')
fold 1, train log rmse 0.170491, valid log rmse 0.156932
fold 2, train log rmse 0.162477, valid log rmse 0.190369
fold 3, train log rmse 0.163763, valid log rmse 0.168232
fold 4, train log rmse 0.167880, valid log rmse 0.154698
fold 5, train log rmse 0.163108, valid log rmse 0.182893
5-fold validation: avg train log rmse: 0.165544, avg valid log rmse: 0.170625

\(K\)-kat çapraz geçerlemedeki hata sayısı önemli ölçüde daha yüksek olsa bile, bir dizi hiper parametre için eğitim hatası sayısının bazen çok düşük olabileceğine dikkat edin. Bu bizim aşırı öğrendiğimizi gösterir. Eğitim boyunca her iki sayıyı da izlemek isteyeceksiniz. Daha az aşırı öğrenme, verilerimizin daha güçlü bir modeli destekleyebileceğini gösteremez. Aşırı öğrenme, düzenlileştirme tekniklerini dahil ederek kazanç sağlayabileceğimizi gösterebilir.
4.10.8. Tahminleri Kaggle’da Teslim Etme¶
Artık iyi bir hiper parametre seçiminin ne olması gerektiğini bildiğimize göre, onu eğitmek için tüm verileri de kullanabiliriz (çapraz geçerleme dilimlerinde kullanılan verinin yalnızca \(1-1/K\)’ı yerine). Bu şekilde elde ettiğimiz model daha sonra test kümesine uygulanabilir. Tahminlerin bir csv dosyasına kaydedilmesi, sonuçların Kaggle’a yüklenmesini kolaylaştıracaktır.
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'train log rmse {float(train_ls[-1]):f}')
# Ağı test kümesine uygula
preds = net(test_features).asnumpy()
# Kaggle'a dış aktarmak için yeniden biçimlendirin
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'train log rmse {float(train_ls[-1]):f}')
# Ağı test kümesine uygula
preds = net(test_features).detach().numpy()
# Kaggle'a dış aktarmak için yeniden biçimlendirin
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'train log rmse {float(train_ls[-1]):f}')
# Ağı test kümesine uygula
preds = net(test_features).numpy()
# Kaggle'a dış aktarmak için yeniden biçimlendirin
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)
Güzel bir makulluk kontrolü, test kümesindeki tahminlerin \(K\)-kat
çapraz geçerleme sürecindekilere benzeyip benzemediğini görmektir.
Yaparsa, Kaggle’a yükleme zamanı gelmiştir. Aşağıdaki kod,
submission.csv adlı bir dosya oluşturacaktır.
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
train log rmse 0.162327

train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
train log rmse 0.162397

train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)
train log rmse 0.162585

Sonra, Fig. 4.10.3 içinde gösterildiği gibi, tahminlerimizi Kaggle’a gönderebilir ve test kümesindeki gerçek ev fiyatları (etiketler) ile nasıl karşılaştırıldıklarını görebiliriz. Adımlar oldukça basittir:
Kaggle web sitesinde oturum açın ve ev fiyatı tahmin yarışması sayfasını ziyaret edin.
“Tahminleri Teslim Et” (“Submit Predictions”) veya “Geç Teslimat” (“Late Submission”) düğmesine tıklayın (bu yazı esnasında düğme sağda yer almaktadır).
Sayfanın alt kısmındaki kesik çizgili kutudaki “Teslimat Dosyasını Yükle” (“Upload Submission File”) düğmesini tıklayın ve yüklemek istediğiniz tahmin dosyasını seçin.
Sonuçlarınızı görmek için sayfanın altındaki “Teslim Et” (“Make Submission”) düğmesine tıklayın.
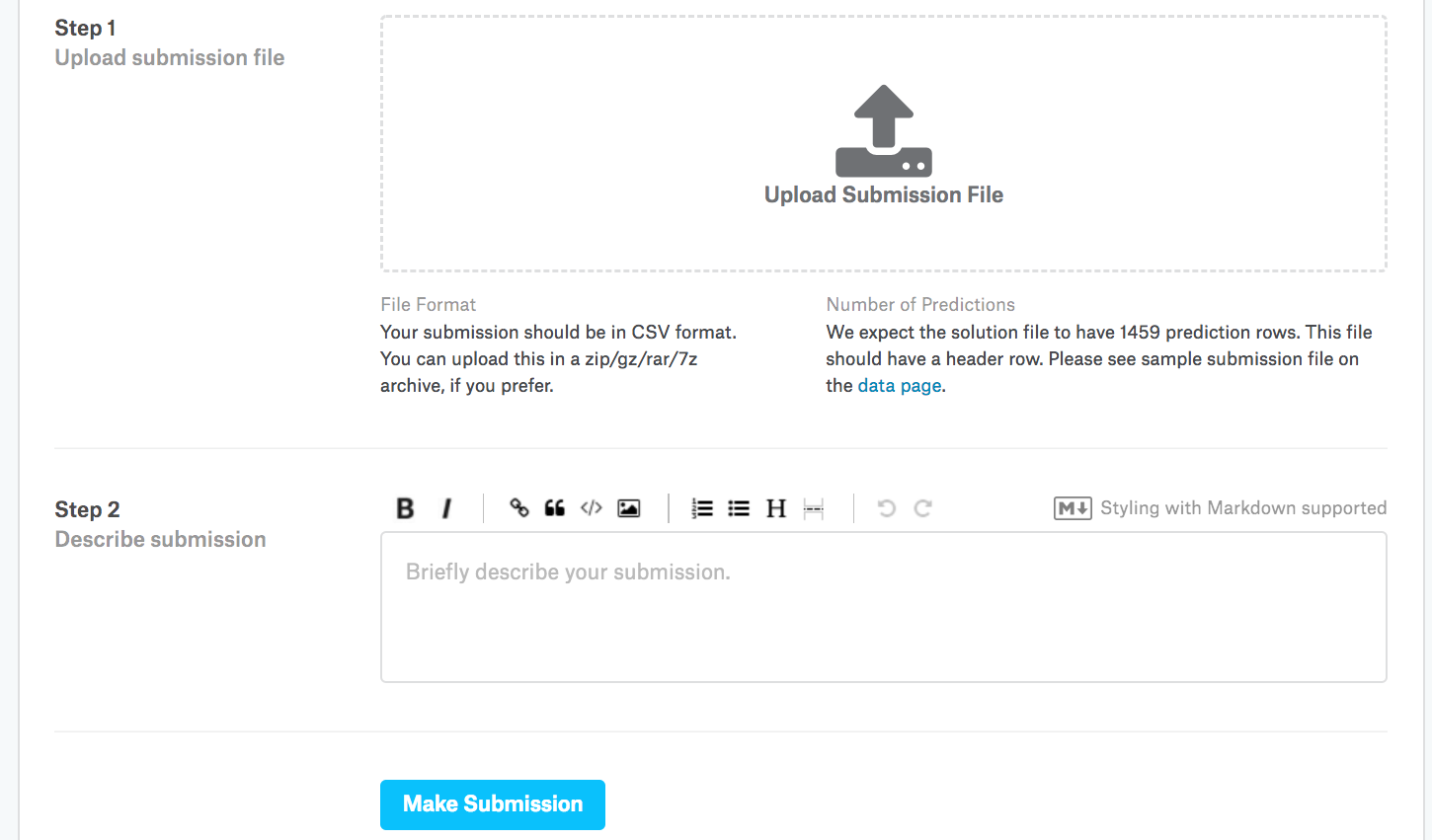
Fig. 4.10.3 Kaggle’a veriyi gönderme¶
4.10.9. Özet¶
Gerçek veriler genellikle farklı veri türlerinin bir karışımını içerir ve önceden işlenmesi gerekir.
Gerçek değerli verileri sıfır ortalamaya ve birim varyansına yeniden ölçeklemek iyi bir varsayılandır. Eksik değerleri ortalamalarıyla değiştirmek de öyle.
Kategorik öznitelikleri gösterge özniteliklere dönüştürmek, onları bire bir vektörler gibi ele almamızı sağlar.
Modeli seçmek ve hiper parametreleri ayarlamak için \(K\)-kat çapraz geçerleme kullanabiliriz.
Logaritmalar göreceli hatalar için faydalıdır.
4.10.10. Alıştırmalar¶
Bu bölümdeki tahminlerinizi Kaggle’a gönderin. Tahminleriniz ne kadar iyi?
Fiyatın logaritmasını doğrudan en aza indirerek modelinizi geliştirebilir misiniz? Fiyat yerine fiyatın logaritmasını tahmin etmeye çalışırsanız ne olur?
Eksik değerleri ortalamalarıyla değiştirmek her zaman iyi bir fikir midir? İpucu: Değerlerin rastgele eksik olmadığı bir durum oluşturabilir misiniz?
\(K\)-kat çapraz geçerleme yoluyla hiper parametreleri ayarlayarak Kaggle’daki puanı iyileştiriniz.
Modeli geliştirerek puanı iyileştirin (örn. katmanlar, ağırlık sönümü ve hattan düşürme).
Bu bölümde yaptığımız gibi sayısal sürekli öznitelikleri standartlaştırmazsak ne olur?